
- 1章 Python入門
- 2章 パーセプトロン
- 3章 ニューラルネットワーク
- 4章 ニューラルネットワークの学習
- 5章 誤差伝播法
- 6章 学習に関するテクニック
- 7章 畳み込みニューラルネットワーク
- 8章 ディープラーニング

1章 Python入門
章のまとめ
- Pythonはシンプルで覚えやすいプログラミング言語である。
- Pythonはオープンソースで自由に使うことができる。
- 本書のディープラーニングの実装ではPython 3系を利用する。
- 外部ライブラリとしてNumPyとMatplotlibを利用する。
- Pythonの実行モードには「インタプリタ」と「スクリプトファイル」の2つのモードがある。
- Pythonでは関数やクラスといったモジュールとして実装をまとめることができる。
- NumPyには多次元配列を操作するための便利なメッソドが数多くある。
2章 パーセプトロン
章のまとめ
- パーセプトロンは入出力を備えたアルゴリズムである。ある入力を与えたら、決まった値が出力される。
- パーセプトロンでは、「重み」と「バイアス」をパラメータとして設定する。
- パーセプトロンを用いれば、ANDやORゲートなどの論理回路を表現できる。
- XORゲートは単層のパーセプトロンでは表現できない。
- 2層のパーセプトロンを用いれば、XORゲートを表現することができる。
- 単層のパーセプトロンは線形領域だけしか表現できないのに対して、多層のパーセプトロンは非線形領域を表現することができる。
- 多層のパーセプトロンは、(論理上)コンピュータを表現できる。
- 複数の信号を入力として受け取り、ひとつの信号を出力する。
- ニューロンでは、送られてきた信号の総和が計算され、その総和がある限界値を超えた場合のみ1を出力する。【ニューロンが発火する】

| x1, x2 | 入力信号 |
|---|---|
| y | 出力信号 |
| w1, w2 | 重み(weight) |
| ○ | ニューロン、ノード |
| パーセプトロンの動作原理 |
|---|
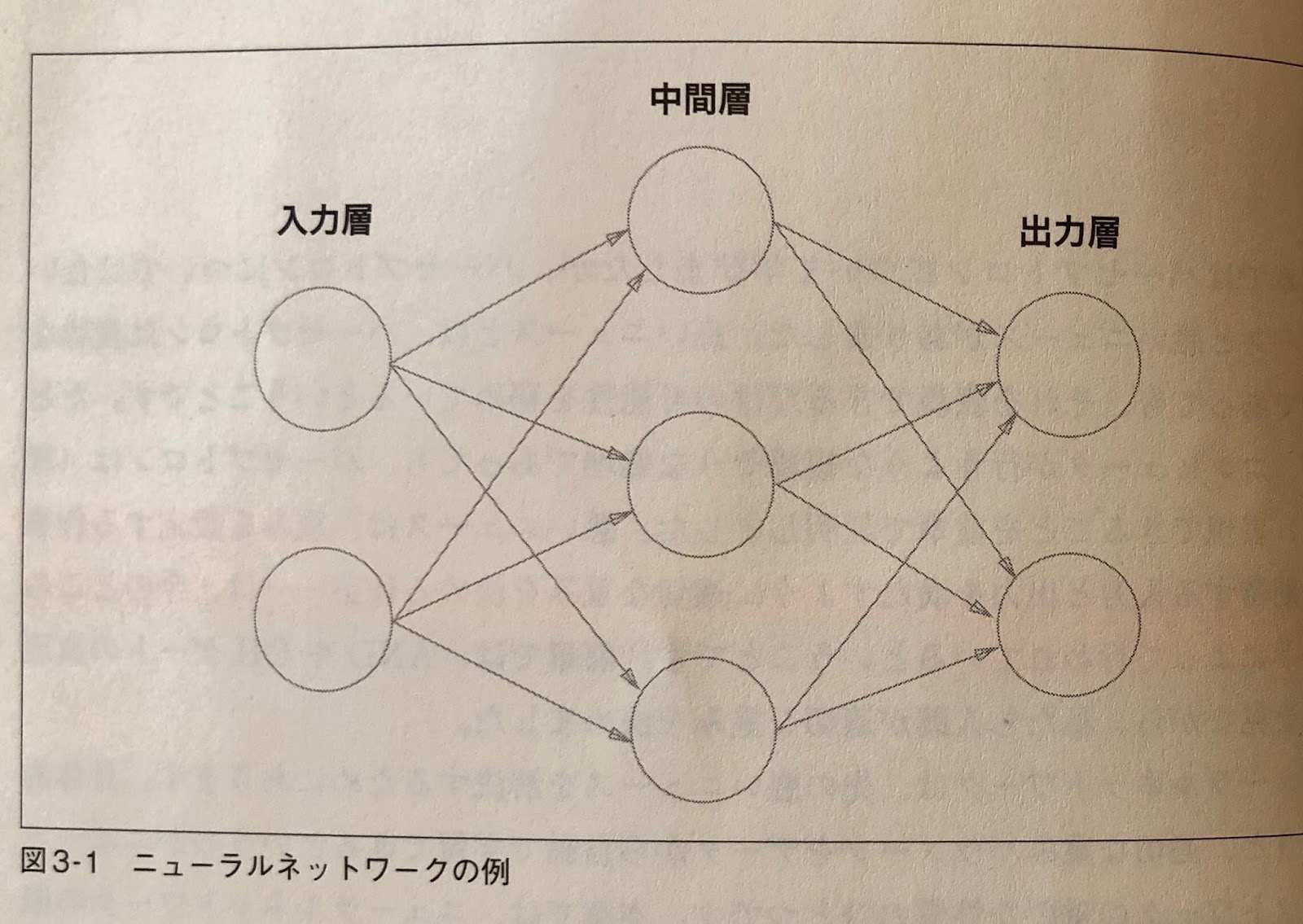
3章 ニューラルネットワーク
章のまとめ
- ニューラルネットワークでは、活性化関数としてシグモイド関数やReLU関数のような滑らかに変化する関数を利用する。
- NumPyの多次元配列をうまく使うことで、ニューラルネットワークを効率よく実装することができる。
- 機械学習の問題は、回帰問題と分類問題に大別できる。
- 出力層で使用する活性化関数は、回帰問題では恒等関数、分類問題ではソフトマックス関数を一般的に利用する。
- 分類問題では、出力層のニューロンの数を分類するクラス数に設定する。
- 入力データのまとまりをバッチと言い、バッチ単位で推論処理を行うことで、計算を高速に行うことができる。
ニューラルネットワーク (neural network)
活性化関数 (activation function)
| 活性化関数 | |
|---|---|
| パーセプトロン |
ステップ関数 
|
| ニューラル ネットワーク |
シグモイド関数
|
ReLU(Rectified Linear Unit)関数
|
多次元配列の計算




回帰問題と分類問題
| 機械学習が対象とする問題 | 出力層の活性化関数 | |||
|---|---|---|---|---|
| 回帰問題 | ある入力データから、(連続的な)数値を予測する問題。 | 例)画像から体重を予測する。 | 恒等関数 | 入力をそのまま出力にする。 |
| 分類問題 | データがどのクラスに属するかを分類する問題。 | 例)画像から男か女かを分類する。 | ソフトマックス 関数 |
yk = exp(ak) / Σ exp(ai) 分母にすべての入力信号が含まれるので、出力はすべての入力信号から影響を受ける。 |
実装
import numpy as np
# ネットワークの重みとバイアスを初期化する
def init_network():
network = {}
# 第1層の設定(2行3列)
network['W1'] = np.array([[0.1, 0.3, 0.5], \
[0.2, 0.4, 0.6]])
# 第2層の設定(3行2列)
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], \
[0.2, 0.5], \
[0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
# 第3層の設定(出力層)(2行2列)
network['W3'] = np.array([[0.1, 0.3], \
[0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
# 入力信号をネットワークで処理し、出力信号を得る
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# 第1層の処理
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1) # 活性化関数:今回はシグモイド関数
# 第2層の処理
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
# 第3層(出力)の処理
a3 = np.dot(z2, W3) + b3
y = identity_function(a3) # 出力層の活性化関数:今回は恒等関数
return y
# シグモイド関数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 恒等関数
def identity_function(x):
return x
# メイン
network = init_network()
x = np.array([1.0, 0.5]) # 入力信号(1行2列)
y = forward(network, x) # 出力信号
print(y) # [ 0.31682708 0.69627909]
4章 ニューラルネットワークの「学習」
章のまとめ
- 機械学習で使用するデータセットは、訓練データとテストデータに分けて使用する。
- 訓練データで学習を行い、学習したモデルの汎化能力をテストデータで評価する。
- ニューラルネットワークの学習は、損失関数を指標として、損失関数の値が小さくなるように、重みパラメータを更新する。
- 重みパラメータを更新する際には、重みパラメータの勾配を利用して、勾配方向に重みの値を更新する作業を繰り返す。
- 微小な値を与えたときの差分によって微分を求めることを数値微分と言う。
- 数値微分によって、重みパラメータの勾配を求めることができる。
- 数値微分による計算には時間がかかるが、その実装は簡単である。一方、次章で実装するやや複雑な誤差逆伝播法は、高速に勾配を求めることができる。
-
【学習】:訓練データから最適な重みパラメータの値を自動で取得すること。
- 「訓練データ」と「テストデータ」を使うのが基本。
- まずは、訓練データだけを使って学習を行い、最適なパラメータを探索する。そして、テストデータを使ってモデルの実力を評価する。
-
【損失関数 (loss function)】:学習を評価する指標。
- 2乗和誤差 (mean squared error)
- 交差エントロピー誤差 (cross entropy error)
- 【特微量】:入力データから本質的なデータを抽出できるように設計された変換器。
-
ニューラルネットワークは、特微量までも機械が学習する。

- 【過学習(overfitting)】:あるデータだけに過度に対応した状態。

損失関数
-
「訓練データを使って学習する」
=「訓練データに対する損失関数を求め、その値をできるだけ小さくするようなパラメータを探し出す」 -
なぜ「認識精度」ではなく「損失関数」?
- 「微分(勾配)」の値を手がかりにパラメータの値を徐々に更新し、探し出す。
- 「認識精度」を指標にすると、微分がほとんどの場所で0になってしまい、パラメータの更新ができない。
- 「認識精度」はパラメータの微小な変化にほとんど反応を示さない。
| 2乗和誤差 (mean squared error) |
|
|---|---|
| 交差エントロピー誤差 (cross entropy error) |
y = log x 
正解ラベルに対応する出力が大きければ大きいほど0に近づく。 |
数値微分
- 微分とは、ある瞬間の変化の量を表したもの。
def numerical_diff(f, x): h = 1e-4 # 0.0001 return (f(x+h) - f(x-h)) / (2 * h)
- 【偏微分】:複数の変数からなる関数の微分。複数ある変数の中でターゲットとする変数をひとつに絞り、他の変数はある値に固定する。
勾配
- 【勾配】:すべての変数の偏微分をベクトルとしてまとめたもの。
| 微分 | |
|---|---|
| 偏微分 | |
| 勾配 |
def numerical_gradient(f, x):
# f・・・(関数)勾配を求める対象の関数。
# x・・・(配列)関数fの変数の値。関数fが2次関数ならば要素数は2。
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # xと同じ形状の配列を生成
for idx in range(x.size):
# 関数fの変数x[idx]による微分値を求める。
# i.e., idx番目の変数値を微小(h)に変化させたときの、関数fの変化を調べる。
# 「idx番目の変数値」以外の変数値は固定 = 偏微分
tmp_x = x[idx]
# f(x+h) の計算
x[idx] = tmp_x + h
fxh1 = f(x)
# f(x-h) の計算
x[idx] = tmp_x - h
fxh2 = f(x)
# 関数fを変数x[idx]で微分した値 → grad[idx]
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_x # もとの値に戻す
# 勾配
# = 関数fをそれぞれの変数(x0, x1, x2, ...)で
# 微分した値がセットされた配列grad
return grad
勾配法
- 【勾配法(gradient method)】
- 勾配をうまく利用して関数の最小値を探す。
- 現在の場所から勾配方向に一定の距離だけ進む。これを繰り返し、関数の値を徐々に減らす。
| 勾配法 | η ・・・学習率(learning rate) |
|---|
def gradient_descent(f, init_x, lr=0.01, step_num=10):
x = init_x
for i in range(stemp_num):
grad = numerical_gradient(f, x) #勾配(数値微分)
x -= lr * grad #勾配に学習率を掛けた値で更新
return x
# /Users/koya/deep-learning-from-scratch-master/ch04/my_two_layer_net.py
import sys, os
import numpy as np
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
from dataset.mnist import load_mnist
#-------------------
# 関数:シグモイド関数
#-------------------
def sigmoid(x):
return 1 / (1 + np.exp(-x))
#-------------------
# 関数:ソフトマックス
#-------------------
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
return exp_a / sum_exp_a
#-------------------
# 関数:交差エントロピー誤差
#-------------------
def cross_entropy_error(y, t):
# 正解ラベルrに対応する出力が大きければ大きいほど0に近く
# 例. t = [ 0, 0, 1, 0, 0, 0, 0, 0]
# y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.0]
delta = 1e-7 # log(0)対策のための微小値
return -np.sum(t * np.log(y + delta))
#-------------------
# 関数:配列xの各要素に対して勾配(数値微分)を求める
#-------------------
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index # 数値ではなく文字列。例. "(0, 1)" とか "(3, 4)" など。
tmp_val = x[idx]
x[idx] = float(tmp_val) + h #他の要素
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 値を元に戻す
it.iternext()
return grad
#==============================
# クラス:2層ネットワーク
#==============================
class TowLayerNet:
# .params
# ニューラルネットワークのパラメータを保持するディクショナリ変数
# .grads
# 勾配を保持するディクショナリ変数
#-------------------
# 初期化
#-------------------
def __init__(self,
input_size, # 入力層のニューロンの数(例. 784 入力画像サイズ28*28)
hidden_size, # 隠れ層のニューロンの数(例. 100)
output_size, # 出力層のニューロンの数(例. 10)
weight_init_std=0.01): #
# 重みとバイアスの初期化
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
#-------------------
# 推論
#-------------------
def predict(self, x): # x:画像データ
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1) # 活性化関数
a2 = np.dot(z1, W2) + b2
y = softmax(a2) # 出力層の活性化関数
return y
#-------------------
# 損失関数
#-------------------
def loss(self, x, t): # x:画像データ, t:正解ラベル
y = self.predict(x)
return cross_entropy_error(y, t) # 交差エントロピー誤差
#-------------------
# 認識精度
#-------------------
def accuracy(self, x, t): # x:画像データ, t:正解ラベル
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
#-------------------
# 勾配(数値微分)(重みパラメータに対する勾配を求める。)
#-------------------
def numerical_gradient(self, x, t): # x:画像データ, t:正解ラベル
loss_W = lambda W: self.loss(x, t) # lambda式による無名関数の定義
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
#==============================
# メイン
#==============================
# (訓練画像, 訓練ラベル), (テスト画像, テストラベル)
(x_train, t_train), (x_test, t_test) = \
load_mnist(normalize=True, one_hot_label=True)
# 訓練データ 画像 x_train (60000, 784) 「縦28×横28」の画像データが 60000枚
# ラベル t_train (60000, 10) one-hotで正解を表現しているため10
# テストデータ 画像 x_test (10000, 784)
# ラベル t_test (10000, 10)
train_loss_list = []
train_acc_list = []
test_acc_list = []
# ハイパーパラメータ
iters_num = 10000 # 繰り返しの回数を適宜設定する
train_size = x_train.shape[0] # 6000
batch_size = 100
learning_rate = 0.1
# 1エポックあたりの繰り返し数
# ※エポック数とは、「一つの訓練データを何回繰り返して学習させるか」の数のこと
iter_per_epoch = max(train_size / batch_size, 1)
# ネットワークの生成
network = TowLayerNet(input_size=784, hidden_size=100, output_size=10)
print(network.params['W1'].shape) # 784行 100列
print(network.params['b1'].shape) # 100行 1列
print(network.params['W2'].shape) # 100行 10列
print(network.params['b2'].shape) # 10行 1列
# 入力層(784ニューロン)
# ○
# ○
# ○ 隠れ層(100ニューロン)
# ○ ○
# ○ ○
# ○ ○ 出力層(10ニューロン)
# ○ ○ ○
# ○ ○ ○
# ○ ○ ○
# ○ ○ ○
# ○ ○ ○
# ○ ○
# ○ ○
# ○ ○
# ○
# ○
# ○
# W1 W2
# b1 b2
for i in range(iters_num):
print("iteration:" + str(i))
# ミニバッチの取得(60000枚の訓練データから100枚だけランダムに抜き出す)
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask] # (100, 784)
t_batch = t_train[batch_mask] # (100, 10)
# 勾配の計算
grad = network.numerical_gradient(x_batch, t_batch)
# パラメータの更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 損失関数値の取得
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 1エポックごとに認識精度を計算
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# グラフの描画
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
5章 誤差逆伝播法
章のまとめ
- 計算グラフを用いれば、計算過程を視覚的に把握することができる。
- 計算グラフのノードは局所的な計算によって構成される。局所的な計算が全体の計算を構成する。
- 計算グラフの順伝播は、通常の計算を行う。一方、計算グラフの逆伝播によって、各ノードの微分を求めることができる。
- ニューラルネットワークの構成要素をレイヤとして実装することで、勾配の計算を効率的に求めることができる(誤差逆伝播法)。
- 数値微分と誤差逆伝播法の結果を比較することで、誤差逆伝播法の実装に誤りがないことを確認できる(勾配確認)。
6章 学習に関するテクニック
章のまとめ
- パラメータの更新方法には、SGD(Stochastic Gradient Descent : 確率的勾配降下法)の他に、有名なものとして、Momentum や AdaGrad、Adam などの手法がある。
- 重みの初期値の与え方は、正しい学習を行う上で非常に重要である。
- 重みの初期値として、「Xavierの初期値」や「Heの初期値」などが有効である。
- Batch Normalization を用いることで、学習を速く進めることができ、また、初期値に対してロバストになる。
- 過学習を抑制するための正規化の技術として、Weight decay や Dropout がある。
- ハイパーパラメータの探索は、良い値が存在する範囲を徐々に絞りながら進めるのが効率の良い方法である。
7章 畳み込みニューラルネットワーク
章のまとめ
- CNN(Convolutional Neural Network:畳み込みNN)は、これまでの全結合層のネットワークに対して、畳込み層とプーリング層が新たに加わる。
- 畳込み層とプーリング層は、im2col(画像を行列に展開する関数)を用いるとシンプルで効率の良い実装ができる。
- CNNの可視化によって、層が深くなるにつれて高度な情報が抽出されていく様子が分かる。
- CNNの代表的なネットワークには、LeNet と AlexNet がある。
- ディープラーニングの発展に、ビッグデータとGPUが大きく貢献している。
8章 ディープラーニング
章のまとめ
- 多くの問題では、ネットワークを深くすることで、性能の恒常が期待できる。
- ILSVRC と呼ばれる画像認識のコンペティションの最近の動向は、ディープラーニングによる手法が上位を独占し、使われるネットワークもディープ化している。
- 有名なネットワークには、VGG、GoogLeNex、ResNet がある。
- GPUや分散学習、ビット精度の削減などによってディープラーニングの高速化を実現できる。
- ディープラーニング(ニューラルネットワーク)は、物体認識だけではなく、物体検出やセグメンテーションに利用できる。
- ディープラーニングを用いたアプリケーションとして、画像のキャプション生成、画像の生成、強化学習などがある。最近では、自動運転へのディープラーニングの利用も期待されている。